資訊檢索中,在進行文字處理時,我們常會進行以下的步驟:
1. Tokenization: 斷詞
2. 過濾stopwords
3. Normalization: 將斷開的詞都變成標準的形式
舉例來說: U.S.A -> USA, on-line -> online;通常使用rule-based
a).通通小寫
b).去掉hyphen, period
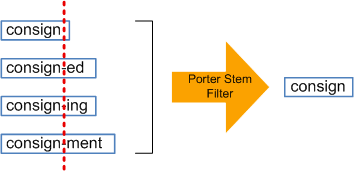
4. Stemming 與 Lemmatization:
a). Stemming: 通常是粗糙的過程,將字的尾巴去掉。
舉例來說: automate, automatic, automation -> automat
b). Lemmatization: 使用形態分析等方式,將字還原成原始字。
舉例來說: am,are,is -> be
在這篇文章中,我要介紹 Stemming中常用的 Porter Stemming Algorithm 使用方式。
首先,請到 http://tartarus.org/martin/PorterStemmer/。
接著找到下圖中的 java

這個Java是一個程式碼,請把它貼到你自己的程式上(新開一個類別來貼),下圖即是該程式碼的樣子,其中main函數裡面的部分就是它教你怎使用他的程式。

不過我覺得有點複雜,所以我用更簡單的範例帶給大家看,所以你可以用我的程式碼,把原本上圖中的main通通換掉。
public static void main(String[] args)
{
//建立一個Stemmer類別 s
Stemmer s = new Stemmer();
//以下是要處理的字
String str = "protected";
//之後將字串轉成字元進行處理
char temp [] = new char[str.length()];
temp=str.toCharArray();
s.add(temp, str.length());
//進行stem步驟
s.stem();
//輸出結果
System.out.println("原本的字 "+str);
System.out.println("Stemming後的字 "+s.toString());
}
貼好後執行看看,程式也很簡潔易懂。
文章標籤
全站熱搜


 留言列表
留言列表